Search Results:
Note - Go, Concurrency Patterns
posted on 02 Nov 2021 under category note in series ref-go
See
- Book: Concurrency in Go
Problem
Race Condition
A “race condition” occurs when two or more operations must execute in the correct order, but the program has not been written so that this order is guaranteed to be maintained.
“Data Race”: one process trying to read while another trying to write.
Atomicity
An operation is “atomic” if it’s indivisible, or uninterruptible within a context. Indivisible or uninterruptible means things happen in its entirety. Context is the scope when we consider what’s “entirety”, an operation is atomic in one context does not necessarily mean it still is in another.
Atomicity is important because if something is atomic:
- implicitly it is safe within concurrent contexts. This allows us to compose logically correct programs
- it can even serve as a way to optimize concurrent programs.
Consider this statement:
i++
It’s NOT atomic even it seems simple, it actually consist of several operation:
- Retrieve the value of i.
- Increment the value of i.
- Store the value of i to i.
We can force atomicity by employing various techniques. The art then becomes determining which areas of your code need to be atomic, and at what level of granularity.
Memory Access Synchronization, Critical Section
The section of your program that needs exclusive access to a shared resource is called a “critical section”.
Deadlock
When all concurrent processes are waiting on one another. In this state, the program will never recover without outside intervention. We call this situation a “deadlock”.
There are a few conditions that must be present for deadlock to happen, known as “Coffman Conditions”:
- Mutual Exclusion: A concurrent process holds exclusive rights to a resource at any one time.
- Wait For Condition: A concurrent process must simultaneously hold a resource and be waiting for an additional resource.
- No Preemption: A resource held by a concurrent process can only be released by that process
- Circular Wait: A concurrent process (P1) must be waiting on a chain of other concurrent processes(P2), which are in turn waiting on it (P1)
If we ensure that at least one of these conditions is not true, we can prevent deadlocks from occurring. Unfortunately, in practice these conditions can be hard to reason about, and therefore difficult to prevent.
Livelock
“Livelock” means both actively performing concurrent operation, but these operation do nothing to move the state of program foward. (two people in hallway).
Livelock is subset of problem “starvation”, except they starve equally.
A common reason for livelock is: two or more concurrent processes attempting to prevent a deadlock without coordination.
Starvation
Starvation means concurrent process cannot get all the resources it needs to perform work. Comparing to livelock, which starved equally, more broadly, starvation usually implies that there are one or more greedy concurrent process that are unfaily preventing others from accomplishing works.
A technique for identifying the starvation is by using a metric. Starvation makes for a good argument for recording and sampling metrics. One of the ways you can detect and solve starvation is by logging when work is accomplished, and then determining if your rate of work is as high as you expect it.
Starvation can cause not only inefficiency, it can also completely pervent another process from accomplishing work.
Any resource must be shared is a candidate for starvation: cpu, mem, file, db, net…
If you utilize memory access synchronization, you’ll have to find a balance between preferring coarse-grained synchronization for performance, and fine-grained synchronization for fairness. When it comes time to performance tune your application, to start with, I highly recommend you constrain memory access synchronization only to critical sections; if the synchronization becomes a performance problem, you can always broaden the scope. It’s much harder to go the other way.
Design for Concurrency Safety
Document your concurrent tion to address:
- Who is responsible for the concurrency?
- How is the problem space mapped onto concurrency primitives?
- Who is responsible for the synchronization?
// CalculatePi calculates digits of Pi between the and end place.
//
// Internally, CalculatePi will create FLOOR((end-)/2) concurrent processes
// which recursively call CalculatePi. Synchronization of writes to pi are
// handled internally by the Pi struct.
CalculatePi(begin, end int64, pi *Pi)
Modeling Your Code
Concurrency vs Parallelism
The difference between concurrency and parallelism turns out to be a very powerful abstraction when modeling your code, and Go takes full advantage of this.
Concurrency is a property of the code; parallelism is a property of the running program.
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
Consider that we wrote our code with the intent that two chunks of the program will run in parallel, but if it’s run on a machine with only one core, then it’s NOT running in parallel. The important things to note are:
- We do not write parallel code, only concurrent code that we hope will be run in parallel. Once again, parallelism is a property of the runtime of our program, not the code.
- It is possible to be ignorant of whether our concurrent code is actually running in parallel. This is only made possible by the layers of abstraction that lie beneath our program’s model: the concurrency primitives, the program’s runtime, the operating system, the platform the operating system runs on (in the case of hypervisors, containers, and virtual machines), and ultimately the CPUs. These abstractions are what allow us to make the distinction between concurrency and parallelism, and ultimately what give us the power and flexibility to express ourselves.
- Parallelism is a function of time, or context. This is important because the context you define is closely related to the concept of concurrency and correctness. Just as atomic operations can be considered atomic depending on the context you define, concurrent operations are correct depending on the context you define. It’s all relative.
As we moving down the stack of abstraction, the problem of modeling things concurrently is becoming both more difficult to reason about, and more important. Conversely, our abstractions are becoming more and more important to us. In other words, the more difficult it is to get concurrency right, the more important it is to have access to concurrency primitives that are easy to compose. Unfortunately, most concurrent logic in our industry is written at one of the highest levels of abstraction: OS threads.
Before Go was first revealed to the public, this was where the chain of abstraction ended for most of the popular programming languages. If you wanted to write concurrent code, you would model your program in terms of threads and synchronize the access to the memory between them. If you had a lot of things you had to model concurrently and your machine couldn’t handle that many threads, you created a thread pool and multiplexed your operations onto the thread pool.
Go has added another link in that chain: the goroutine. In addition, Go has borrowed several concepts from the work of famed computer scientist Tony Hoare, and introduced new primitives for us to use, namely channels. Threads are still there, of course, but we find that we rarely have to think about our problem space in terms of OS threads. Instead, we model things in goroutines and channels, and occasionally shared memory.
Why is this important? How Go’s decoupling concurrency and parallelism can help us?
- Goroutines free us from having to think about our problem space in terms of parallelism and instead allow us to model problems closer to their natural level of concurrency. This is achieved by a promise Go makes to us: that goroutines are lightweight, and we normally won’t have to worry about creating one. There are appropriate times to consider how many goroutines are running in your system, but doing so upfront is soundly a premature optimization. Contrast this with threads where you would be wise to consider such matters upfront.
- Go’s runtime multiplexes goroutines onto OS threads automatically and manages their scheduling for us. This means that optimizations to the runtime can be made without us having to change how we’ve modeled our problem; this is classic separation of concerns. As advancements in parallelism are made, Go’s runtime will improve, as will the performance of your program – all for free.
- Because Go’s runtime is managing the scheduling of goroutines for you, it can introspect on things like goroutines blocked waiting for I/O and intelligently reallocate OS threads to goroutines that are not blocked. This also increases the performance of your code.
- Because the problems we work on as developers are naturally concurrent more often than not, we’ll naturally be writing concurrent code at a finer level of granularity than we perhaps would in other languages. This finer level of granularity enables our program to scale dynamically when it runs to the amount of parallelism possible on the program’s host.
- Channels are inherently composable with other channels. This makes writing large systems simpler because you can coordinate the input from multiple subsystems by easily composing the output together. You can combine input channels with timeouts, cancellations, or messages to other subsystems. Coordinating mutexes is a much more difficult proposition.
- The select statement is the complement to Go’s channels and is what enables all the difficult bits of composing channels. select statements allow you to efficiently wait for events, select a message from competing channels in a uniform random way, continue on if there are no messages waiting, and more.
Memory Synchronizations vs CSP primitives
Go support for two style for concurrency. CSP was and is a large part of what Go was designed around; however, Go also supports more traditional means of writing concurrent code through memory access synchronization and the primitives that follow that technique. Structs and methods in the sync and other packages allow you to perform locks, create pools of resources, preempt goroutines, and more.
One of Go’s mottos is “Share memory by communicating, don’t communicate by sharing memory.” That said, Go does provide traditional locking mechanisms in the sync package. Most locking issues can be solved using either channels or traditional locks. So which should you use? Use whichever is most expressive and/or most simple.
The way we can mostly differentiate comes from where we’re trying to manage our concurrency: internally to a tight scope, or exter‐ nally throughout our system. Here is a decision tree to help you decide:
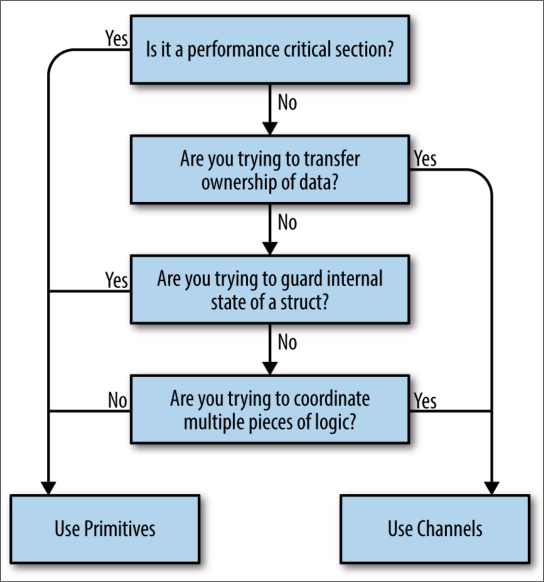
When working with Go, it’s best to discard common patterns for OS thread concurrency like thread pools: aim for simplicity, use channels when possible, and treat goroutines like a free resource.
Goroutine
Thread, Goroutine, Coroutin
Goroutines are unique to Go (though some other languages have a concurrency primitive that is similar). They’re not OS threads, and they’re not exactly “green threads” – threads that are managed by a language’s runtime – they’re a higher level of abstraction known as “coroutines”. Coroutines are simply concurrent subroutines (functions, closures, or methods in Go) that are nonpreemptive – that is, they cannot be interrupted. Instead, coroutines have multiple points throughout which allow for suspension or reentry.
What makes goroutines unique to Go are their deep integration with Go’s runtime. Goroutines don’t define their own suspension or reentry points; Go’s runtime observes the runtime behavior of goroutines and automatically suspends them when they block and then resumes them when they become unblocked. In a way this makes them preemptable, but only at points where the goroutine has become blocked. It is an elegant partnership between the runtime and a goroutine’s logic. Thus, goroutines can be considered a special class of coroutine.
M:N
Go’s mechanism for hosting goroutines is an implementation of what’s called an M:N scheduler, which means it maps M green threads to N OS threads. Goroutines are then scheduled onto the green threads. When we have more goroutines than green threads available, the scheduler handles the distribution of the goroutines across the available threads and ensures that when these goroutines become blocked, other goroutines can be run.
Fork-Join Model
Go follows a model of concurrency called the fork-join model. The word fork refers to the fact that at any point in the program, it can split off a child branch of execution to be run concurrently with its parent. The word join refers to the fact that at some point in the future, these concurrent branches of execution will join back together. Where the child rejoins the parent is called a “join point”.
The go statement is how Go performs a fork. Join points are what guarantee our program’s correctness and remove the race condition. In order to a create a join point, you have to synchronize the main goroutine and the other goroutines. This can be done in a number of ways like using sync.Waitgroup.Wait().
Closure
“Closures” close around the lexical scope they are created in, thereby capturing variables. Since goroutines execute within the same address space they were created in, if you run a closure in a goroutine, the closure operate on a copy of these variables.
Lightweight
A newly minted goroutine is given a few kilobytes, which is almost always enough. When it isn’t, the run-time grows (and shrinks) the memory for storing the stack automatically, allowing many goroutines to live in a modest amount of memory. The CPU overhead averages about three cheap instructions per function call. It is practical to create hundreds of thousands (million) of goroutines in the same address space.
Regarding the memory size that a noop goroutine takes, for 8GB of RAM, we can spin up millions of goroutines without requiring swapping:
Memory (GB) Goroutines (#/100,000) Order of magnitude
2^0 3.718 3
2^1 7.436 3
2^2 14.873 6
2^3 29.746 6
2^4 59.492 6
2^5 118.983 6
2^6 237.967 6
2^7 475.934 6
2^8 951.867 6
2^9 1903.735 9
Regarding context-switching, our benchmark shows that it takes 225ns per context switch for goroutines, 92% faster than OS context switch.
Creating goroutines is very cheap, and so you should only be discussing their cost if you’ve proven they are the root cause of a performance issue.
GOMAXPROCS
In the runtime package, there is a function called GOMAXPROCS. In my opinion, the name is misleading: people often think this function relates to the number of logical processors on the host machine – and in a roundabout way it does – but really this function controls the number of OS threads that will host so-called “work queues.”
The sync Package
WaitGroup
See basic/sync/waitgroup.
Mutex, RWMutex
See basic/sync/mutex.
It’s usually advisable to use RWMutex instead of Mutex when it logically makes sense.
Cond
…a rendezvous point for goroutines waiting for or announcing the occurrence of an event.
An “event” is any arbitrary signal between two or more goroutines that carries no information other than the fact that it has occurred.
Naive approachs would be:
// 1. this would consume all cycles of one core:
for conditionTrue() == false {
}
// 2. still inefficient, have to figure out the right sleeping time:
for conditionTrue() == false {
time.Sleep(1*time.Millisecond)
}
It would be nice if there is a way for a goroutine to efficiently sleep until it was signaled to wake and check its condition, this is what Cond for.
Typical pattern when using Cond:
// Newcond() receive a sync.Locker interface value, which allow Cond
// faciliatate coordination with other goroutines in concurrent-safe way.
c := sync.NewCond(&sync.Mutex{})
// It's necessary to Lock the locker because the call to Wait automatically
// calls Unlock on the locker when entered.
c.L.Lock()
for conditionTrue() == false {
// calling Wait will block and suspend the goroutine, wait to be notified.
c.Wait()
}
// It's necessary to Unlock the locker because when call to Wait exits, it will
// automatically calls Lock on the locker.
c.L.Unlock()
Note since Wait() will auto call Unlock() when enter and Lock() when exit, so Lock before Wait and Unlock after awoken is essential, this also mean although it looks like we hold a lock the entire block, but it’s NOT. The call to Wait doesn’t just block, it suspends the current goroutine, allowing other goroutines to run on the OS thread.
Unicast and Broadcast
How do we notify the Wait blocked goroutine to check the condition? there are two ways: unicast event with Signal() and broadcast event with Broadcast().
Internally, the runtime maintains a FIFO list of goroutines waiting to be signaled; Signal finds the goroutine that’s been waiting the longest and notifies it, whereas Broadcast sends a signal to all goroutines that are waiting.
VS Channels
We can trivially reproduce Signal with channels but reproducing the behavior of repeated calls to Broadcast would be more difficult. This is something channels can’t do easily and thus is one of the main reasons to utilize the Cond type.
In addition, the Cond type is much more performant than utilizing channels.
Like most other things in the sync package, usage of Cond works best when constrained to a tight scope, or exposed to a broader scope through a type that encapsulates it.
Once
sync.Once is a type that utilizes some sync primitives internally to ensure that only one call to Do ever calls the function passed in – even on different goroutines.
sync.Once only counts the number of times Do is called, not how many times unique functions passed into Do are called. In this way, copies of sync.Once are tightly coupled to the functions they are intended to be called with.
I recommend that you formalize this coupling by wrapping any usage of sync.Once in a small lexical block: either a small function, or by wrapping both in a type.
Pool
Pool is a concurrent-safe implementation of the object pool pattern. the pool pattern is a way to create and make available a fixed number, or pool, of things for use. It’s commonly used to constrain the creation of things that are expensive.
The object pool design pattern is best used either when you have concurrent processes that require objects, but dispose of them very rapidly after instantiation, or when construction of these objects could negatively impact memory.
There is one thing to be wary of when determining whether or not you should utilize a Pool: if the code that utilizes the Pool requires things that are not roughly homogenous, you may spend more time converting what you’ve retrieved from the Pool than it would have taken to just instantiate it in the first place.
Channel
Channels are one of the synchronization primitives in Go derived from Hoare’s CSP. While they can be used to synchronize access of the memory, they are best used to communicate information between goroutines.
Channel Behavior
Operation Channel State Result
-------------------------------------------------------------------
read nil block
open and not empty value
open and empty block
closed default value, false
write only compile error
write nil block
open and full block
open and not full write value
closed panic !!
receive only compile error
close nil panic !!
open and not empty close channel, read succeed until drained,
then reads produce default value
open and empty close channel, read produces default value
closed panic !!
receive only compile error
Buffered Channel
An unbuffered channel has a capacity of zero and so it’s already full before any writes. A buffered channel with no receivers and a capacity of four would be full after four writes, and block on the fifth write since it has nowhere else to place the fifth element. Like unbuffered channels, buffered channels are still blocking; the preconditions that the channel be empty or full are just different.
If a buffered channel is empty and has a receiver, the buffer will be bypassed and the value will be passed directly from the sender to the receiver. In practice, this happens transparently.
Buffered channels can be useful in certain situations, but you should create them with care. buffered channels can easily become a premature optimization and also hide deadlocks by making them more unlikely to happen.
An valid usage of buffered channels for optimization is: if a goroutine making writes to a channel has knowledge of how many writes it will make, it can be useful to create a buffered channel whose capacity is the number of writes to be made, and then make those writes as quickly as possible. But there are caveats using buffered channelss, see #Queue.
Design
How can we organize channels to make using them more robust and stable?
The first thing we should do to put channels in the right context is to assign channel ownership. I’ll define ownership as being a goroutine that instantiates, writes, and closes a channel. Much like memory in languages without garbage collection, it’s important to clarify which goroutine owns a channel in order to reason about our programs logically. Unidirectional channel declarations are the tool that will allow us to distinguish between goroutines that own channels and those that only utilize them: channel owners have a write-access view into the channel (chan or chan<-), and channel utilizers only have a read-only view into the channel (<-chan).
Once we make this distinction between channel owners and nonchannel owners, the results from the preceding table follow naturally, then we can begin to assign responsibilities to goroutines that own channels and those that do not.
Responsibility
Owner Consumer
--------------------------------------------------------------
creation read
write / pass ownership handle block:timeout/stop/forever...
close handle close
ecapsulate / expose
We should try to do what we can in our programs to keep the scope of channel ownership small so that these things remain obvious. If you have a channel as a member variable of a struct with numerous methods on it, it’s going to quickly become unclear how the channel will behave.
Select
If channels are the glue that binds goroutines together, then the select statement is the glue that binds channels together; it’s how we’re able to compose channels together in a program to form larger abstractions, and that’s the real fun when we start composing channels to form higher-order concurrency design patterns. select statements can help to safely bring channels together with concepts like cancellations, timeouts, waiting, and default values.
Each case has an equal chance of being selected. The reasoning behind this is: the Go runtime cannot know anything about the intent of your select statement; that is, it cannot infer your problem space or why you placed a group of channels together into a select statement. Because of this, the best thing the Go runtime can hope to do is to work well in the average case.
Confinement
When working with concurrent code, there are a few different options for safe operation:
- Synchronization primitives for sharing memory (e.g., sync.Mutex)
- Synchronization via communicating (e.g., channels)
Implicitly safe options:
- Immutable data
Each concurrent process may operate on the same data, but it may not modify it. If it wants to create new data, it must create a new copy of the data with the desired modifications. This allows not only a lighter cognitive load on the developer, but can also lead to faster programs if it leads to smaller critical sections(or eliminates them altogether). In Go, you can achieve this by writing code that utilizes copies of values instead of pointers to values in memory.
- Data protected by confinement
“Confinement” ensure information is only ever available from one concurrent process. When this is achieved, a concurrent program is implicitly safe and no synchronization is needed. There are two kinds of confinement possible:
-
“Ad hoc confinement” is when you achieve confinement through a convention. sticking to convention is difficult to achieve on projects of any size unless you have tools to perform static analysis on your code every time someone commits some code.
-
“Lexical Confinement” involves using lexical scope to expose only the correct data and concurrency primitives for multiple concurrent processes to use. It makes it impossible to do the wrong thing.
Lexical Confinement VS Synchronization
Why pursue confinement when we have synchronization available to us? The answer is improved performance and reduced cognitive load on developers. Synchronization comes with a cost, and if you can avoid it you won’t have any critical sections, and therefore you won’t have to pay the cost of synchronizing them. You also sidestep an entire class of issues possible with synchronization; developers simply don’t have to worry about these issues. Concurrent code that utilizes lexical confinement also has the benefit of usually being simpler to understand than concurrent code without lexically confined variables. This is because within the context of your lexical scope you can write synchronous code.
For-Select Loop
for-select is often being used in these scenarios:
- Sending iteration variables out on a channel.
for _, s := range []string{"a", "b", "c"} {
select {
case <-done:
return
case stringStream <- s:
}
}
- Looping infinitely waiting to be stopped.
// Variant 1: keep the select as short as possible
for {
select {
case <-done:
return
default:
}
// Do non-preemptable work
}
// Variant 2: embeds works in the default clause.
for {
select {
case <-done:
return
default:
// Do non-preemptable work
}
}
Preventing Goroutine Leaks By Cancellation
Goroutine need to stop when:
- When it has completed its work.
- When it cannot continue its work due to an unrecoverable error.
- When it’s told to stop working.
We get the first two stop path for free – your algorithm.
For the third path – “work cancellation” – it’s the most important bit because of the “network effect”: if you’ve begun a goroutine, it’s most likely cooperating with several other goroutines in some sort of organized fashion. We could even represent this interconnectedness as a graph: whether or not a child goroutine should continue executing might be predicated on knowledge of the state of many other goroutines. The parent goroutine (often the main goroutine) with this full contextual knowledge should be able to tell its child goroutines to terminate.
We’ll continue looking at large-scale goroutine interdependence later, but for now let’s consider how to ensure a single child goroutine is guaranteed to be cleaned up.
Cancellation
How we ensure goroutines are able to be stopped can differ depending on the type and purpose of goroutine, but they all build on the foundation of passing in a done channel. We can establish a signal between the parent goroutine and its children that allows the parent to signal cancellation to its children. By convention, this signal is usually a read-only channel named done. The parent goroutine passes this channel to the child goroutine and then closes the channel when it wants to cancel the child goroutine.
We can stipulate a convention: If a goroutine is responsible for creating a goroutine, it is also responsible for ensuring it can stop the goroutine.
Or-Channel
Sometimes we may want to combine one or more done channels into a single done channel that closes if any of its component channels close. To do this:
- If we know the number of done channels, It is perfectly acceptable, albeit verbose, to write a select statement that performs this coupling.
- However, sometimes you can’t know the number of done channels you’re working with at runtime, or just prefer a one-liner. In those cases, we can combine these channels together using the “or-channel pattern”.
This pattern creates a composite done channel through recursion and goroutines. It is useful to employ at the intersection of modules in your system. At these intersections, you tend to have multiple conditions for canceling trees of goroutines through your call stack. Using the Or function, you can simply combine these together and pass it down the stack.
Another way of doing this is context. See #context.
Error Handling Inside Concurrent Goroutines
Because a concurrent process is operating independently of its parent or siblings, it can be difficult for it to reason about what the right thing to do with the error is. So concurrent processes should send their errors to another part of your program that has complete information about the state of your program, and can make a more informed decision about what to do.
If a goroutine can produce errors, those errors should be tightly coupled with its result type, and passed along through the same lines of communication – just like regular synchronous functions.
Pipeline
A “pipeline” is just another tool we can use to form an abstraction in our system. It is a very powerful tool to use when your program needs to process streams, or batches of data. A pipeline is nothing more than a series of things that take data in, perform an operation on it, and pass the data back out. We call each of these operations a “stage” of the pipeline.
By using a pipeline, we separate the concerns of each stage, which provides numerous benefits. We can:
- Modify stages independent of one another.
- Mix and match how stages are combined independent of modifying the stages.
- Process each stage concurrent to upstream or downstream stages.
- We can fan-out (See #Fanout).
- Or rate-limit portions of your pipeline.
Stage
Pipeline stages are very closely related to functional programming and can be considered a subset of “monads”. We can combine stages because they must have these proerties:
- A stage consumes and returns the same type.
- A stage must be reified by the language so that it may be passed around. Functions in Go are reified and fit this purpose nicely.
Performance
Generally, the limiting factor on your pipeline will either be your generator, or one of the stages that is computationally intensive. If the generator isn’t creating a stream from memory generators, you’ll probably be I/O bound. Reading from disk or the network may also limit the performance of pipelines.
Speaking of one stage being computationally expensive, how can we help mitigate this? Won’t it rate-limit the entire pipeline? For ways to help mitigate this, See Fan-in, Fan-out.
Constructing With Channel
Channels are uniquely suited to constructing pipelines in Go because they fulfill all of our basic requirements. They can receive and emit values, they can safely be used concurrently, they can be ranged over, and they are reified by the language.
A “generator” function converts a discrete set of values into a stream of data on a channel. Aptly, this type of function is called a generator. You’ll see this frequently when working with pipelines because at the beginning of the pipeline, you’ll always have some batch of data that you need to convert to a channel.
Fan-Out, Fan-In
Stages in your pipeline can be particularly computationally expensive. When this happens, upstream stages in your pipeline can become blocked while waiting for your expensive stages to complete, the pipeline itself can take a long time to execute as a whole.
To address this, we can reuse a single stage of our pipeline on multiple goroutines in an attempt to parallelize pulls from an upstream stage.
“Fan-out” is a term to describe the process of starting multiple goroutines to handle input from the pipeline.
“Fan-in” is a term to describe the process of combining multiple results into one channel.
We might consider fanning out one of your stages if both of the following apply:
- It doesn’t rely on values that the stage had calculated before. The property of order-independence is important because you have no guarantee in what order concurrent copies of your stage will run, nor in what order they will return.
- It takes a long time to run.
Or-Done Channel
At times we will be working with channels from disparate parts of your system, which we don’t have control of, so we can’t make any assertions about how a channel will behave when the goroutine you’re working with is canceled via its done channel. That is to say, you don’t know if the fact that your goroutine was canceled means the channel your goroutine is reading from will have been canceled. For this reason, we’ve learned to wrap our read from the channel with a select statement that also selects from a done channel. This is perfectly fine, but doing so takes code that’s easily read like this:
loop:
for {
select {
case <-done:
break loop
case maybeVal, ok := <-myChan:
if ok == false {
return // or maybe break out of for-loop.
}
// Do something with val
}
}
We wrap the common pattern seen in cancellation and pipeline stages into an or-done channel, so we can get back from the verbosity to a simple for loops like this:
for val := range orDone(done, myChan) {
// Do something with val
}
Tee Channel
Sometimes we may want to split values coming in from a channel so that we can send them off into two separate areas of our codebase. Imagine a channel of user commands: we might want to take in a stream of user commands on a channel, send them to something that executes them, and also send them to something that logs the commands for later auditing.
Tee-channel does this. you pass it a channel to read from, and it will return two separate channels that will get the same value.
Utilizing this pattern, it’s easy to continue using channels as the join points of our system.
Bridge Channel
In some circumstances, we may want to consume values from a sequence of channels:
<-chan <-chan interface{}
This is slightly different than coalescing a slice of channels into a single channel, as we saw in or channel or fan-out/fan-in. A sequence of channels suggests an ordered write, albeit from different sources.
As a consumer, the code not care about the fact that its values come from a sequence of channels. In that case, dealing with a channel of channels can be cumbersome. Instead, we can define a function that can destructure the channel of channels into a simple channel — a technique called “bridging” the channels. We can use bridge to help present a single channel facade over a channel of channels.
Queuing
Sometimes it’s useful to begin accepting work for your pipeline even though the pipeline is not yet ready for more. This process is called “queuing”. It means that once your stage has completed some work, it stores it in a temporary location in memory so that other stages can retrieve it later, and your stage doesn’t need to hold a reference to it.
It’s usually one of the last techniques you want to employ when optimizing your program. Adding queuing prematurely can hide synchronization issues such as deadlocks and livelocks. Queuing will almost never speed up the total runtime of your program; it will only allow the program to behave differently.
The utility of introducing a queue isn’t that the runtime of one of stages has been reduced, but rather that the time it’s in a blocking state is reduced. In this way, the true utility of queues is to decouple stages so that the runtime of one stage has no impact on the runtime of another. Decoupling stages in this manner then cascades to alter the runtime behavior of the system as a whole, which can be either good or bad depending on your system.
Consider this pipeline:
p := processRequest(done, acceptConnection(done, httpHandler))
We wouldn’t want connections to your program to begin timing out because processRequest stage was blocking acceptConnection stage. We want acceptConnection stage to be unblocked as much as possible. In this case, we can use a queue for help.
When And Where
The situation queuing can increase the overall performance of your system are:
- If batching requests in a stage saves time.
Chunking
In bufio.Writer, the writes are queued internally into a buffer until a sufficient chunk has been accumulated, and then the chunk is written out. This process is often called “chunking”.
Chunking is faster because bytes.Buffer must grow its allocated memory to accommodate the bytes it must store. For various reasons, growing memory is expensive; therefore, the less times we have to grow, the more efficient our system as a whole will perform. Thus, queuing has increased the performance of our system as a whole.
Usually anytime performing an operation requires an overhead, chunking may increase system performance. Some examples of this are opening database transactions, calculating message checksums, and allocating contiguous space.
Lookbehind, Ordering
Aside from chunking, queuing can also help if your algorithm can be optimized by supporting lookbehinds, or ordering.
- If delays in a stage produce a feedback loop into the system.
Death-Spiral
If a delay in a stage causes more input into the pipeline, it can lead to a systemic collapse of your upstream systems. This is often referred as a “negative feedback loop”, “downward-spiral”, or even “death-spiral”. Without some sort of fail-safe, the system utilizing the pipeline will never recover.
By introducing a queue at the entrance to the pipeline, you can break the feedback loop at the cost of creating lag for requests. From the perspective of the caller into the pipeline, the request appears to be processing, but taking a very long time. As long as the caller doesn’t time out, your pipeline will remain stable. If the caller does time out, you need to be sure you support some kind of check for readiness when dequeuing. If you don’t, you can inadvertently create a feedback loop by processing dead requests thereby decreasing the efficiency of your pipeline.
In this case, queuing should be implemented either:
- At the entrance to your pipeline.
- In stages where batching will lead to higher efficiency.
Avoid adding queue elsewhere, like after a computationally expensive stage. As we’ve learned, there are only a few situations where queuing will decrease the runtime of your pipeline, and peppering in queuing in an attempt to work around this can have disastrous consequences.
What Size, Little’s Law
In queuing theory, there is a law that — with enough sampling — predicts the throughput of your pipeline. It’s called Little’s Law. It’s commonly expressed as:
L=λW
- L = the average number of units in the system.
- λ = the average arrival rate of units.
- W = the average time a unit spends in the system.
This equation only applies to so-called stable systems. In a pipeline, a “stable system” is one in which the rate that work enters the pipeline, or “ingress”, is equal to the rate in which it exits the system, or “egress”. If the rate of ingress exceeds the rate of egress, your system is unstable and has entered a “death-spiral”. If the rate of ingress is less than the rate of egress, you still have an “unstable” system, but all that’s happening is that your resources aren’t being utilized completely.
So let’s assume that our pipeline is stable. If we want to decrease W, the average time a unit spends in the system by a factor of n, we only have one option: to decrease the average number of units in the system, and we can only decrease the average number of units in the system if we increase the rate of egress: (@?? why NOT nλ ?):
L/n = λ * W/n
Also notice that if we add queues to our stages, we’re increasing L, which either increases the arrival rate of units (nL = nλ * W) or increases the average time a unit spends in the system (nL = λ * nW). Through Little’s Law, we can see that queuing will not help decrease the amount of time spent in a system.
Using little’s law, we can determine:
- How many requests per second our pipeline can handle?
- How large our queue needs to be to handle a desired number of requests?
Let’s how little’s law help us with analysing our pipeline. Suppose we have a pipeline of 3 stages, we can answer these questions with the help of little’s law:
- How many requests per second our pipeline can handle, i.e. what’s the value of λ?
Suppose we’ve enabled sampling and find that 1 request (r) takes about 1 second to make it throught the pipeline (W=1s). Now we plug the value W=1s and L=3r (because each stage in pipeline is processing a request) into the equation:
3r = λr/s * 1s
3r/s = λr/s
λr/s = 3r/s
and get the answer: we can handle three requests per second.
- How large our queue needs to be to handle a desired number of requests?
Suppose our sampling shows a request takes 1ms to process (W=0.0001s), and we want to handle 100,000 requests per second (λ=100000r/s). We plug the values in. We decrement L by 3 because our pipeline have 3 stages.
Lr = 100000r/s * 0.0001s
Lr = 10r
Lr - 3r = 7r
and get the answer: our queue should have a capacity of 7.
Persistent Queue
Something that Little’s Law can’t provide insight on is handling failure. Keep in mind that if for some reason your pipeline panics, you’ll lose all the requests in your queue. To mitigate this, you can either stick to a queue size of zero, or you can move to a “persistent queue”, which is simply a queue that is persisted somewhere that can be later read from should the need arise.
Context Package
The context package let us communicate extra information alongside the simple notification to cancel: why the cancellation was occuring, or whether or not our function has a deadline by which it needs to complete. It serves two primary purposes:
- To provide an API for canceling branches of your call-graph.
- To provide a data-bag for transporting request-scoped data through your callgraph.
API
Context Type
type Context interface {
// Deadline returns the time when work done on behalf of this context should
// be canceled. Deadline returns ok==false when no deadline is set.
// Successive calls to Deadline return the same results.
Deadline() (deadline time.Time, ok bool)
// Done returns a channel that's closed when work done on behalf of this
// context should be canceled. Done may return nil if this context can
// never be canceled. Successive calls to Done return the same value.
Done() <-chan struct{}
// Err returns a non-nil error value after Done is closed. Err returns
// Canceled if the context was canceled or DeadlineExceeded if the
// context's deadline passed. No other values for Err are defined. After
// Done is closed, successive calls to Err return the same value.
Err() error
// Value returns the value associated with this context for key, or nil if
// no value is associated with key. Successive calls to Value with the same
// key returns the same result.
Value(key interface{}) interface{}
}
The Context type will flow through your system much like a done channel does, it’s important to always pass instances of Context into your functions. It can be created with these two functions:
func Background() Context
func TODO() Context
Background simply returns an empty Context. TODO is not meant for use in production, but also returns an empty Context; TODO’s intended purpose is to serve as a placeholder for when you don’t know which Context to utilize, or if you expect your code to be provided with a Context, but the upstream code hasn’t yet furnished one.
Cancellation
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
func WithDeadline(parent Context, deadline time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)
WithCancel returns a new Context that closes its done channel when the returned cancel function is called. WithDeadline returns a new Context that closes its done channel when the machine’s clock advances past the given deadline. WithTimeout returns a new Context that closes its done channel after the given timeout duration.
Scoped Data
- The key must satisfy Go’s notion of comparability; that is, the equality operators == and != need to return correct results when used.
- Values returned must be safe to access from multiple goroutines.
Smart Cancel Logic
Context help us if we want to do something like:
- Parent operation only wants to wait one second before abandoning the call to a slow subroutine.
- If one operation is unsuccessful, we also want to cancel another.
- For slow operation, it might want to check whether a deadline is given.
Customized Key Type
Since both the Context’s key and value are defined as interface{}, we lose Go’s typesafety when attempting to retrieve values. For these reasons, the Go authors recommend us to follow a few rules when storing and retrieving value from a Context.
- Define a custom key-type in our package. As long as other packages do the same, this prevents collisions within the Context.
- Since we don’t export the keys we use to store the data, we must therefore export functions that retrieve the data for us. This works out nicely since it allows consumers of this data to use static, type-safe functions.
But this approach might introduce a circular reference problem, and coerces the architecture into creating packages centered around data types that are imported from multiple locations. This certainly isn’t a bad thing, but it’s something to be aware of.
Design: What To Store?
The context package hasn’t been uniformly lauded. Within the Go community, the context package has been somewhat controversial. The cancellation aspect of the package has been pretty well received, but the ability to store arbitrary data in a Context, and the type-unsafe manner in which the data is stored, have caused some divisiveness:
- Although we have partially abated the lack of type-safety with custome typed key and accessor functions, we could still introduce bugs by storing incorrect types.
- However, the larger issue is definitely the nature of what developers should store in instances of Context.
Quoting from the official package comments:
Use context values only for request-scoped data that transits processes and API boundaries, not for passing optional parameters to functions.
But this is still ambiguous. The best way I’ve found is to come up with some heuristics with your team, and evaluate them in code reviews. Here are some example heuristics:
-
The data should transit process or API boundaries. If you generate the data in your process’ memory, it’s probably not a good candidate to be request-scoped data unless you also pass it across an API boundary.
-
The data should be immutable. If it’s not, then by definition what you’re storing did not come from the request.
-
The data should trend toward simple types. If request-scoped data is meant to transit process and API boundaries, it’s much easier for the other side to pull this data out if it doesn’t also have to import a complex graph of packages.
-
The data should be data, not types with methods. Operations are logic and belong on the things consuming this data.
-
The data should help decorate operations, not drive them. If your algorithm behaves differently based on what is or isn’t included in its Context, you have likely crossed over into the territory of “optional parameters”.
For example:
Data 1 2 3 4 5
---------------------------------------------------------
Request ID Y Y Y Y Y
User ID Y Y Y Y
URL Y Y
API Authorization Token Y Y Y Y
Request Token Y Y Y
Design: Verbosity Or Dependency?
Another dimension to consider is how many layers this data might need to traverse before utilization. If there are a few frameworks and tens of functions between where the data is accepted and where it is used, do you want to lean toward verbose, self documenting function signatures, and add the data as a parameter? Or would you rather place it in a Context and thereby create an invisible dependency? There are merits to each approach, and in the end it’s a decision you and your team will have to make.
Error Propagation
We should carefully considering how issues propagate through our system, and how they end up being represented to the user.
Let consider what info should an “error” contain:
- What happened. e.g., “disk full,” “socket closed,” or “credentials expired.” we can decorate this with some context that will help the user.
- When and where it occurred. Errors should always contain a complete stack trace starting with how the call was initiated and ending with where the error was instantiated. The stack trace should not be contained in the error message(more on this in a bit), but should be easily accessible when handling the error up the stack. Further, the error should contain information regarding the context it’s running within. For example, in a distributed system, it should have some way of identifying what machine the error occurred on. Later, when trying to understand what happened in your system, this information will be invaluable. In addition, the error should contain the time on the machine the error was instantiated on, in UTC.
- A friendly user-facing message. The message that gets displayed to the user should be customized to suit your system and its users. It should only contain abbreviated and relevant information from the previous two points. A friendly message is human-centric, gives some indication of whether the issue is transitory, and should be about one line of text.
- How the user can get more information. At some point, someone will likely want to know, in detail, what happened when the error occurred. Errors that are presented to users should provide an ID that can be cross-referenced to a corresponding log that displays the full information of the error: time the error occurred (not the time the error was logged), the stack trace – everything you stuffed into the error when it was created. It can also be helpful to include a hash of the stack trace to aid in aggregating like issues in bug trackers.
Mal-formed Bugs and Well-formed Errors
We can take the stance that any error that is propagated to the user without this information is a mistake, and therefore a bug.
This requires that at the boundaries of each component, all incoming errors must be wrapped in a well-formed error for the component our code is within. Hence any error that escapes our module without our module’s error type can be considered malformed, and a bug.
Note that it is only necessary to wrap errors in these cases:
- at your own module boundaries (public functions/methods)
- or when your code can add valuable context.
Usually this prevents the need for wrapping errors in most of the code.
Log And Display
All errors should be logged with as much information as is available.
But when displaying errors to users, this is where the distinction between bugs and known edge cases comes in.
- When our user-facing code receives a well-formed error, we can be confident that at all levels in our code, care was taken to craft the error message, and we can simply log it and print it out for the user to see.
- When malformed errors, or bugs, are propagated up to the user, we should also log the error, but then display a friendly message to the user stating something unexpected has happened. If we support automatic error reporting in our system, the error should be reported back as a bug. If we don’t, we might suggest the user file a bug report. Note that the malformed error might actually contain useful information, but we cannot guarantee this, since the only guarantee we do have is that the error is not customized, so we should bluntly display a human-centric message about what happened.
Timeout, Cancellation
When designing your concurrent processes, be sure to take into account timeouts and cancellation. Like many other topics in software engineering, neglecting timeouts and cancellation from the beginning and then attempting to put them in later is a bit like trying to add eggs to a cake after it has been baked.
Cancellation is a natual response to a timeout, but let’s analyse timeout and cacellation separately here.
Timout
We might want to support timeout for these reasons:
-
If our system is saturated, its ability to process requests is at capacity, we may want requests at the edges of our system to time out rather than take a long time to field them.
-
Some data has a window within which it must be processed. If a concurrent process takes longer to process the data than this window, we would want to time out and cancel the concurrent process. For instance, if our concurrent process is dequeing a request after a long wait, the request or its data might have become obsolete during the queuing process.
- If this window is known beforehand, it would make sense to pass our concurrent process a context.Context created with context.WithDeadline, or context.WithTimeout.
- If the window is not known beforehand, we’d want the parent of the concurrent process to be able to cancel the concurrent process when the need for the request is no longer present. context.WithCancel is perfect for this purpose.
-
In a large system, especially distributed systems, it can sometimes be difficult to understand the way in which data might flow, or what edge cases might turn up. It is not unreasonable, and even recommended, to place timeouts on all of your concurrent operations to guarantee your system won’t deadlock. The timeout period doesn’t have to be close to the actual time it takes to perform your concurrent operation. The timeout period’s purpose is only to prevent deadlock, and so it only needs to be short enough that a deadlocked system will unblock in a reasonable amount of time for your use case. Note that this isn’t a recommendation for how to build a system correctly; rather a suggestion for building a system that is tolerant to timing errors you may not have exercised during development and testing. I do recommend you keep the timeouts in place, but the goal should be to converge on a system without deadlocks where the timeouts are never triggered.
Cancellation
We’ve seen to ways to implement cancellation: done channel and Context type. When writing concurrent code that can be terminated at any time, we need to keep this considerations in head:
- Preemptability.
- Shared State.
- Duplicated Messages.
Preemptablility
Look at this code:
reallyLongCalculation := func(
done <-chan interface{},
value interface{},
) interface{} {
intermediateResult := longCalculation(value)
select {
case <-done:
return nil
default:
}
return longCalculation(intermediateResult)
}
We’ve made the effort using the done channel to make reallyLongCalculation to be preemptable, but notice that it can only be preempted between the two longCalculation function calls, should we continue and make longCalculation also preemptable?
The guideline is: Define the period within which our concurrent process is preemptable, and ensure that any functionality that takes more time than this period is itself preemptable. An easy way to do this is to break up the pieces of your goroutine into smaller pieces. You should aim for all nonpreemptable atomic operations to complete in less time than the period you’ve deemed acceptable.
Shared State
If our goroutine happens to modify shared state, like a database, a file, an in-memory data structure, what happens when the goroutine is canceled? Does our goroutine try and roll back the intermediary work it’s done? How long does it have to do this work?
If we keep the modifications to any shared state within a tight scope, and/or ensure those modifications are easily rolled back, we can usually handle cancellations pretty well. If possible, build up intermediate results in-memory and then modify state as quickly as possible.
Duplicated Messages
Let’s say you have a pipeline with three stages: a generator stage, stage A, and stage B. The generator stage monitors stage A by keeping track of how long it’s been since it last read from its channel, and brings up a new instance, A2, if the current instance becomes nonperformant. If that were to happen, it is possible for stage B to receive duplicate messages.
We can handle this problem with these approaches:
- Heartbeat (See #Heartbeat).
- If your algorithm allows it, or your concurrent process is idempotent, you can simply allow for the possibility of duplicate messages in your downstream processes and choose whether to accept the first or last message you receive.
- You can use bidirectional communication with your parent to explicitly request permission to send your message. However, in practice, this is rarely necessary, and since it is more complicated than heartbeats, and heartbeats are more generally useful, I suggest you just use heartbeats.
Heartbeat
Heartbeats are a way for concurrent processes to signal life to outside parties. They allow us insights into our system, and they can make testing the system deterministic when it might otherwise not be.
We discuss two type of heartbeat here:
- Heartbeats that occur on a time interval.
- Heartbeats that occur at the beginning of a unit of work.
We will take the concept of heartbeat further in #Healing_Unhealty_Goroutines.
Heartbeat At Time Interval
Time-interval based heartbeat is useful for concurrent code that might be waiting for something else to happen for it to process a unit of work. Because the goroutine that processing those units of works doesn’t know when that work might come in, it might be sitting around for a while waiting for something to happen. A heartbeat is a way to signal to its listeners that everything is well, and that the silence is expected.
In a properly functioning system, heartbeats aren’t that interesting. We might use them to gather statistics regarding idle time, but the utility for interval-based heartbeats really shines when your goroutine isn’t behaving as expected. By using a heartbeat, we can avoid deadlock, and remain deterministic by not having to rely on a longer timeout.
Heartbeat At Work Begin
This kind of heartbeat is extremely useful for tests, interval-based heartbeats can be used in the same fashion, but if you only care that the goroutine has started doing its work, this style of heartbeat is simpler.
Replicated Requests
If receiving a response as quickly as possible is the top priority, we can make a trade-off: either replicate the request to multiple handlers(whether those be goroutines, processes, or servers), and one of them will return faster than the other ones; we can then immediately return the result. The downside is that you’ll have to utilize resources to keep multiple copies of the handlers running.
If this replication is done in-memory, it might not be that costly, but if replicating the handlers requires replicating processes, servers, or even data centers, this can become quite costly. The decision you’ll have to make is whether or not the cost is worth the benefit.
This pattern have a caveat we need to watch out: all of your handlers need to have equal opportunity to service the request. Otherwise we might lose the chance receiving the result from the fastest handler because it can’t service the request. Also, whatever resources the handlers are using to do their job need to be replicated as well.
A different symptom of the same problem is “uniformity”. If our handlers are too much alike, the chances that any one will be an outlier is smaller. You should only replicate out requests like this to handlers that have different runtime conditions: different processes, machines, paths to a data store, or access to different data stores altogether. Although this can be expensive to set up and maintain, if speed is our goal, it is a valuable technique. In addition, this technique also provides fault tolerance and scalability.
Rate Limiting
Rate limiting is typically used in service API to achieve these goals:
- Prevent attackes like DDoS.
- Prevent the effect of overloading cascade through the system.
- Keep the performance gurantees to our users.
- Keep our system’s performance and stability in boundaries, if we need to expand those boundaries, we can do so in a controlled manner.
But note that rate limiting can also be used by users, i.e. to keep the API budgets in control.
In a basic rate limiting implementation, there is only one rate limiter; for more complex requirements, we can also implment a mult-tier rate limiting, in which request is limited by the first restrictive-enough rate limiter.
Also, aside from limiting rate by time, we can limit by other dimensions like disk access, network access, etc.
Token Bucket
Most rate limiting is done by utilizing an algorithm called the “token bucket”: every time you need to access a resource, you reach into the bucket and remove a token.
When implementing token bucket, there are two settings we can fiddle with:
- the “depth” of the bucket: how many tokens are available for immediate use.
- the rate at which tokens are replenished.
Using these two we can control both the “burstiness” and “overall rate limit”. Burstiness simply means how many requests can be made when the bucket is full.
Healing Unhealthy Goroutines
In long-lived processes such as daemons, goroutines are usually blocked, waiting on data to come to them through some means, so that they can wake up, do their work, and then pass the data on. Sometimes the goroutines are dependent on a resource that you don’t have very good control of. The point is that it can be very easy for a goroutine to become stuck in a bad state from which it cannot recover without external help. If you separate your concerns, you might even say that it shouldn’t be the concern of a goroutine doing work to know how to heal itself from a bad state. In a long-running process, it can be useful to create a mechanism that ensures your goroutines remain healthy and restarts them if they become unhealthy. We’ll refer to this process of restarting goroutines as “healing” (much like Erlang’s supervisors).
We’ll call the logic that monitors a goroutine’s health a “steward”, and the goroutine that it monitors a “ward”. Stewards will also be responsible for restarting a ward’s goroutine should it become unhealthy. To do so, it will need a reference to a function that can start the goroutine.